ELI Validator documentation
What is this application ?
It is a validator that checks the conformance of RDF data against a set of rules. The RDF data can be extracted from RDFa or JSON-LD in a webpage, or provided in a 'raw' RDF file. The rules are expressed using the SHACL language (RDF SHapes Constraints Language).
The validator is generic : it can be provided with any set of SHACL rules and any RDF data to check. However it is also specifically adapted to verify the conformance of ELI metadata (European Legislation Identifier) published by European official legal publishers in their webpages.
This application also provides a way to convert ELI metadata into schema.org metadata.
Features
- Validate the structured content of a webpage encoded in RDFa or included as JSON-LD, either by providing an online page URL, or by copy/pasting the HTML code;
- Validate an RDF dataset by uploading an RDF file;
- Use preloaded Shapes files, or upload a customised shape file;
- Display the validation result of the data, organised by shapes;
- Display a shape file itself;
- Run a validation using a command line application;
Limits
The application is not capable of properly displaying any SHACL constraints, only those sufficient for validating ELI data. In particular, it will not be able to properly display SPARQL-based constraints or targets.
The application was developed in January 2016 while the SHACL recommendation was not final (see below). It was updated on 21 March 2017 according to the working draft available at this time. As such, it might use SHACL constructs that did not make their way to the final specification.
The application is available in English only.
3rd-party libraries used
This online SHACL validator is a J2EE application that relies on :
- The open-source SHACL validator from TopQuadrant, doing the actual validation;
- The Apache Jena RDF framework;
- The Semargl RDFa parser;
- The Spring MVC framework;
- The Twitter bootstrap CSS framework and its "Paper" bootswatch variant;
- JQuery;
Background information
ELI (European Legislation Identifier)
The European Legislation Identifier (ELI) is a system to make legislation available online in a standardised format, so that it can be accessed, exchanged and reused across borders.ELI is based on a voluntary agreement between the EU countries.
The initiative relies on semantic web technologies, namely :
-
web identifiers (URIs) to identify legal information;
-
an ontology (in OWL) specifying how to describe legal information;
-
the RDFa or JSON-LD syntaxes for exchanging legislation in machine-readable formats;
You can read more about ELI in the ELI registry on EUR-Lex., or on the eli.fr website.
This validator embeds three predefined SHACL constraint files : one based on the ELI ontology version 1.2, and two based on the preceding versions of the ontology, 1.1 and 1.0.
SHACL (RDF SHapes Constraints Language)
SHACL is a recommendation of the W3C, part of the "data on the web" activity, for describing structural constraints and validating RDF instance data against them. SHACL was issued as a W3C recommendation on the 20th of July 2017.
The constraints in SHACL are expressed in "Shapes". To summarize (in a very simplified way), a Shape is the combination of the following three pieces :
- The target of the shape : it defines which resources in the graph will be validated against the shape. The target is commonly defined as "all the instances of class C" or "all the subjects of property P", but it can also be defined using a SPARQL query for more advanced selection criteria. The nodes in the data graph that are the targets for a given shape are called focus nodes.
- The focus node constraints : they specify constraints that need to be met by the focus node itself, not its property values. Typically, this would be to validate that the URI of the target of the Shape matches a certain regular expression or if the focus node has a given class.
- The property constraints : they specify constraints that need to be met by the properties expressed on the focus node. Typically, this would be to check cardinalities of a given predicate or that the value of a certain predicate has a specific class, are expressed using property constraints.
A SHACL specification is expressed in an RDF file using the SHACL vocabulary. Here is a simple example that encodes that every instance of class "ex:Person" must have at least one "ex:name" :
ex:PersonShape
a sh:NodeShape ;
sh:targetClass ex:Person ;
sh:property ex:PersonShape-name .
ex:PersonShape-name
a sh:PropertyShape ;
sh:path ex:name ;
sh:minCount 1 .
You can read more about SHACL in the RDF Data Shapes W3C working group, and in the official recommendation.
How to use the online validator
Prerequisites
What you need :
- Some data to validate : either encoded in RDFa or JSON-LD in an online webpage, or in a manually crafted HTML page, or in an RDF file;
- (optional) A SHACL file, unless you use one of the predefined files in the application;
- (optional) The ontology file for your data, only if your data model is an extension of the validated data model (e.g. if you have created an extension of the ELI ontology - like in the case of Finland);
Use the validation form
Basic usage
The validation form allows you to run the validator :
-
You have three possibilities to specify where the data you want to validate are :
-
If you want to validate the RDFa/JSON-LD markup of an online webpage, then enter the webpage URL;

-
If your webpage is not online and you have it saved as a local file on your computer, copy/paste its content in the second field;

-
If you have a complete RDF dataset to validate, click on the "validate RDF data" tab, and upload your RDF file here ;

-
-
You have two possibilities to specify the shapes to use for validation :
- Use a shape file that has been preloaded in the application;
- Upload your own shape file (typically if you want to adapt one of the preloaded shape files);
-
Click on validate !
Advanced options
The "advanced options" section allows you to upload a custom ontology file to be used by the validator. You should use this option if you have extended the ELI ontology with your own classes and properties, so that the validator can "understand" how your data model relates to the ELI model on which the predefined shape file is based.
How to read the validation result screen
The validation result screen is organised in three parts : a validation header, a navigation pane, and the list of shapes with the corresponding violations for each shape.
The validation header
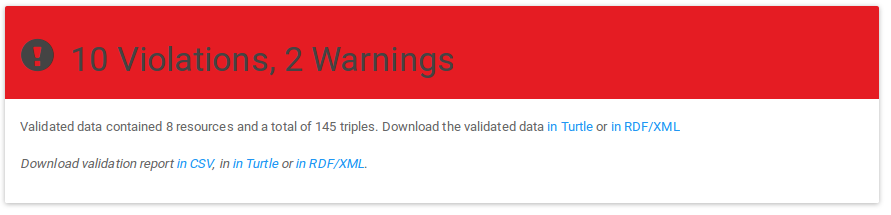
The validation header contains the following elements :
-
The conformance level of the validated data according to the shape file, given by the header colour :
- Red : there is at least one validation result for a Shape with a severity of "Violation" ;
- Yellow : there is no violation, but there is at least one validation result for a Shape with a severity of "Warning";
- Purple : there is no violation, no warning, but at least one validation result for a Shape with a severity of "Info";
- Green : all good ! there is no validation result at all;
- Grey : the validator could not find any target for any of the shapes; in other words, the validator had nothing to validate in your data;
-
The number of total violations, warnings and infos in the validation result; note that this is different from the number of constraints that triggered these results : a single constraint may have triggered more than one validation result;
-
Access to the validated data in RDF (Turtle or RDF/XML); if you validated the content of a webpage, this allows you to retrieve the actual raw data extracted from the RDFa in that webpage. This is this actual raw data that was validated;
-
Access to the validation report in different formats : CSV, Turtle or RDF/XML;
The navigation pane
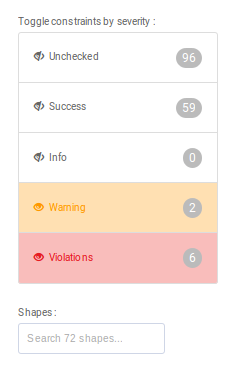
The navigation pane allows you to do the following :
- Hide or show the constraints by severity (Unchecked, Success, Info, Warning, Violation). For the explanation on these severity levels, see the description of shapes in the next section. Next to each severity level is the number of constraints with the corresponding severity level. Note how this is different from the number of total results in the validation report : a single constraint might have triggered more than one validation result.
- Quickly access a shape, by typing its name in the search field;
The shape list
The main body of the result screen is a list of blocks similar to
the one below : 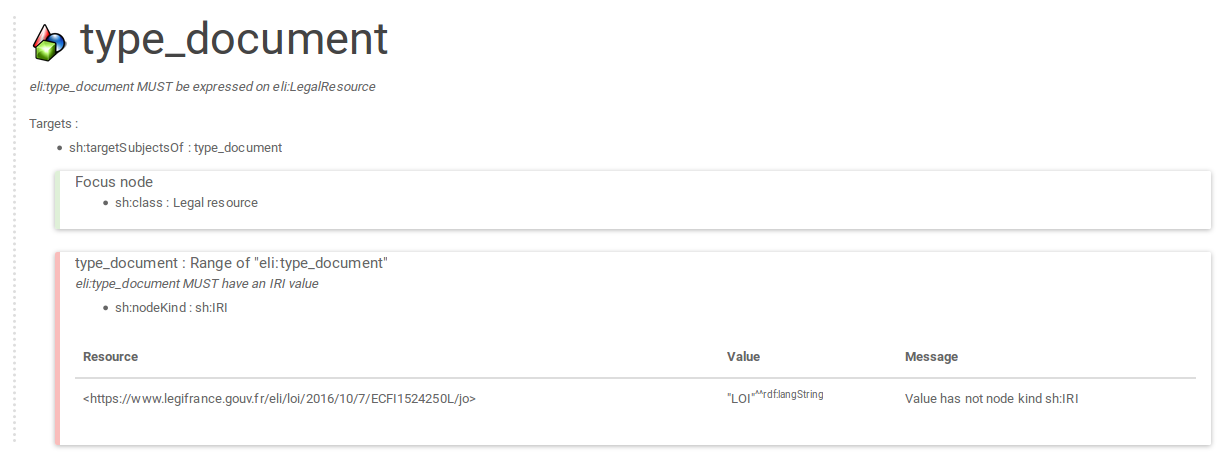
Each block corresponds to a shape, and contains the following elements :
-
The title/name of the shape;
-
A short description of the shape;
-
The definitions of the targets of the shape. Typically this is defined as either "sh:targetsSubjectsOf" (all the subjects of a given property), or "sh:class" (all the instances of a given class);
-
A list of contraints blocks. The first block in the list is the "Focus node" and describes the focus node constraints, the rest describes the property constraints (see the documentation section on the shapes). Each contraint block is structured like this :
-
the colour on the left indicates the validation status of the constraint :
- Grey = Unchecked. "Unchecked" constraints are constraints from shapes that did not match any target in the data (for example if the shape targets all instances of class "Person", but no such instance could be found in the data, then that shape and all its constraints are considered "Unchecked");
- Green = Success. "Success" constraints are constraints from shapes that did match some targets in the data, and no validation results was produced for that constraint;
- Purple = Info;
- Yellow = Warning;
- Red = Violations; "Info", "Warning" and "Violation" constraints are constraints from shapes that did matched some targets in the data, and at least one validation result was produced for that constraint. The severity level (info, warning, violation) is the severity level that was assigned to the constraint in the constraint file.
-
The predicate ("type_document") or predicate path on which the constraint applies, and title for this constraint ("Range of eli:type_document");
-
A short description of the constraint ("eli:type_document MUST have an IRI value");
-
If some validation results were produced from that constraint, then a list of results, consisting of three columns :
- the URI of the resource on which the problem occurs;
- the value that triggered the validation result;
- an information message returned by the SHACL validator;
-
How to customise the ELI shape file used for validation
The ELI validator already has a preloaded file to validate ELI 1.2 metadata. You may wish to adapt this file to your own needs, and provide this customised shape file to the validator instead of the preloaded one.
The ELI 1.2 shape file is actually generated from an Excel file, so customising it can be done easily by editing the Excel file and regenerating the shape file. To do this :
-
Download the ELI 1.2 Excel file from the Shapes registry;
-
Edit and adapt this excel file (out of scope of this documentation, you can refer to the online documentation of the converter); typically you can :
- delete or strikethrough some cells content that you do not want to check anymore;
- adjust the severity level of some shapes (Violation, Warning or Info);
-
Re-generate the RDF Shape file by uploading the Excel in the SKOS Play converter application;
-
Save the generated file;
-
Provide this file to the validator instead of the predefined one;
How to use the validation API
The application also provides two simple REST API calls, both of which operate with content negociation and can
return their result either in RDF (RDF/XML or Turtle) or in CSV
(if text/csv is requested).
GET API
GET
.../api/validate?url=http://url.of.webpage.to.valida.te&shapes=http://url.of.shapes.file.to.u.se
Validate the given URL with the ELI shapes file, and get the result as RDF Turtle :
curl --header "Accept: text/turtle"
"http://localhost:8080/eli-validator/api/validate?url=http://legilux.public.lu/eli/etat/leg/loi/2006/07/31/n2/jo&shapes=shapes/eli-shapes.ttl"
Validate the given URL with the ELI shapes file, and get the result as CSV :
curl --header "Accept: text/csv"
"http://localhost:8080/eli-validator/api/validate?url=http://legilux.public.lu/eli/etat/leg/loi/2006/07/31/n2/jo&shapes=shapes/eli-shapes.ttl"
POST API
POST
.../api/validate?data=Turtle_RDF_content_to_validate&shapes=Turtle_content_of_shapes_to_use
POST some data and a shape file, and get the results in RDF Turtle :
curl -X POST --header "Accept: text/turtle"
-F "data=<eli-shapes-test-case.ttl" -F
"shapes=<eli-shapes.ttl"
http://localhost:8080/eli-validator/api/validate
POST some data and a shape file, and get the results in CSV :
curl -X POST --header "Accept: text/csv" -F
"data=<eli-shapes-test-case.ttl" -F
"shapes=<eli-shapes.ttl"
http://localhost:8080/eli-validator/api/validate
How to use the command line validator
Prerequisites
- Make sure Java 8 is installed on your computer;
- Make sure your have a Shape file on your local computer. You can download one from the shape registry;
Run the command line
-
Open a command line prompt in the directoy where you downloaded the validator, and run
java -jar shacl-validator-X-Y-onejar.jar --help; You should see the usage instructions below; -
You need to provide the following parameters to the online validator ;
-
the input data to validate, which can be either :
- a local RDF file in your computer;
- a webpage URL, starting with "http" ("https" works too), in which case the RDFa parsing will be attempted on the content of the HTML;
-
the path to the SHACL rule file to use;
-
the path to where you want to store the output of the validation, which can be either :
- a file ending with "csv", in which case the output will be generated as CSV;
- a file ending with "rdf" or "ttl" to produce the corresponding Turtle or RDF/XML serialisation of the validation result;
-
Here is a typical invocation example :
java -jar shacl-validator-X.Y-onejar.jar
validate -i input.ttl -s shapes.ttl -o output.csv
The usage instruction of the command line validation is the following :
java -jar shacl-validator-1.0-SNAPSHOT-onejar.jar --help
Usage: <main class> [options] [command] [command options]
Options:
-h, --help
Prints the help message
Default: false
-l, --log
Reference to a log4j configuration file
Commands:
validate Validate an input RDF data or HTML file against the provided
SHACL file, and writes the output in the given output file
Usage: validate [options]
Options:
* -i, --input
Path to a local RDF file, or URL of an HTML page to validate (in
that case RDFa extraction will be attempted on the HTML page)
* -o, --output
Path to the output file; the output file can end in either '.csv'
or any valid RDF syntax extension (.ttl, .rdf, etc.)
* -s, --shapes
Path to an RDF file containing the shapes definitions to use
How to use the crawler/extractor
The crawler/extractor is a simple utility that allows to crawling a website, extracting RDFa/JSON-LD from the crawled pages, storing the extracted triples in an RDF graph, and outputing the resulting graph in a file.
Disclaimer : this is a simple crawler and extractor. Crawling a website intelligently requires an intimate knowledge of its URL structure in order to filter in only interesting pages and leave out the rest. It also requires sufficient infrastructure : for large crawls; both the crawl data and the extracted RDF needs to be stored on a disk and the crawl needs to be resumable if it stops before finishing.
While the provided crawler does allow for a certain customisation of the URLs to crawl as well as it allow to resume the crawl upon errors, it is certainly not suitable for large-scale crawlings of mulitple websites in productions. It has been tested to fetch and extract RDFa/JSON-LD for no more than a few thousand webpages.
Prerequisites
- Make sure Java 8 is installed on your system;
- Make sure your system can run for a long time : the crawl is a very long operation;
- Make sure you have enough memory if you want to store the crawl result in memory (typically 16Gb of RAM);
Run the command line
-
Unzip the file you have downloaded;
-
Open a prompt in the directoy where you unzipped the crawler/extractor, and run
java -jar crawler-extractor-X.Y-onejar.jar --help; You should see the usage instructions of the command; -
Create a configuration file for the crawler by following the documentation included in the package you unzipped :
- read the documentation;
- start from a provided example;
- creating this crawl configuration implies creating the seeds file, which is the file that lists the initial URLs from which the crawler will start following hyperlinks;
-
When the options are adjusted in the configuration file, run the crawler with the command
java -jar crawler-extractor-X.Y-onejar.jar --config path-to-config-file.xml
ELI to schema.org conversion
The ELI to schema.org conversion utility allows to convert structured data expressed in ELI to structured (JSON-LD) data expressed in the schema.org Legislation extension.
The form is similar to the validation form documented above. It can take as an input either the URL of a webpage containing ELI metadata, inline HTML content, or raw RDF data.
This tool is expected to help publishers include schema.org markup in their websites; It is based on a mapping specification. It does not provide an API or a batch to automate the process. The results of the converter should be reviewed before being used, and publishers remain responsible for the metadata inserted into their webpages. Note that there is no guarantee that schema.org markup will be read by search engines, and no guarantee that search engines will actually use this data.
The results of the converter must be included in the <head> tag, inside a <script type="application/ld+json"> :
<script type="application/ld+json">
{
"@graph" : [ {
"@id" : "http://...",
"@type" : "schema:Legislation",
...
} ]
}
</script>